Abstract#
OmniJARVIS presents a unified vision-language-action tokenization framework that enables open-world instruction following agents. This work bridges the gap between language understanding and embodied action execution through a novel tokenization approach.
Introduction#
The ability to follow natural language instructions in open-world environments represents a fundamental challenge in artificial intelligence. Current approaches often struggle with the integration of vision, language, and action modalities, leading to suboptimal performance in complex scenarios.
Architecture#
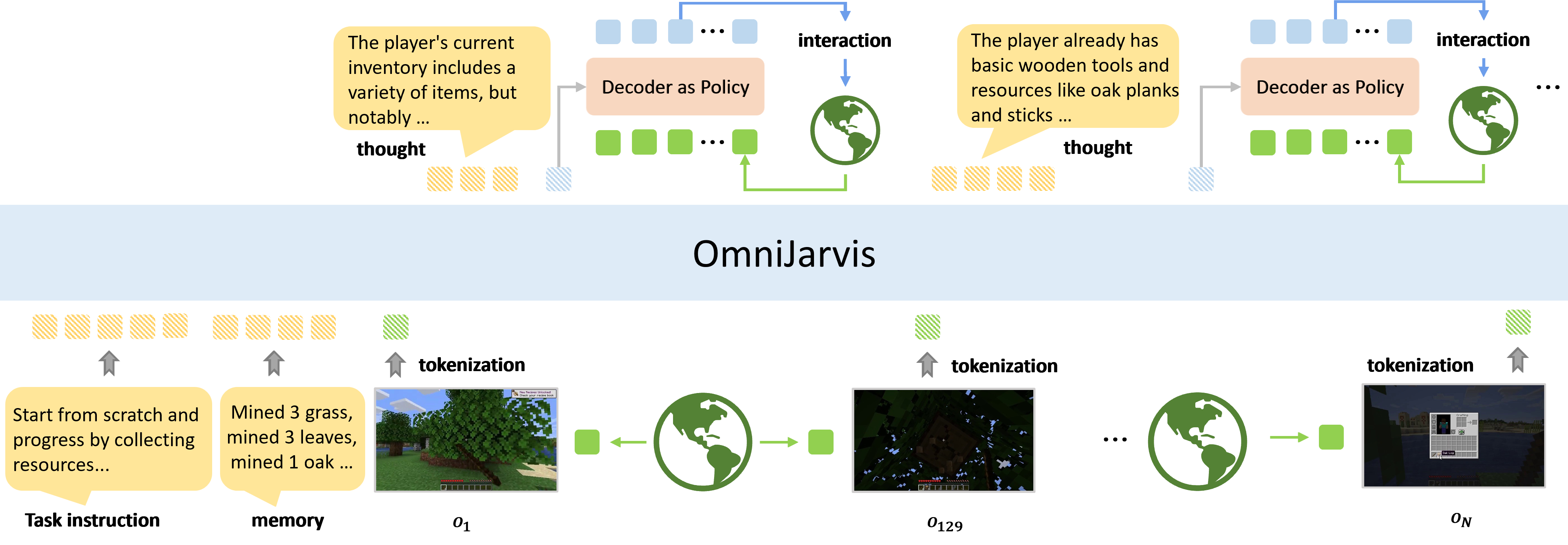
Our unified tokenization approach treats vision, language, and actions as tokens in a shared representation space, enabling seamless multimodal understanding and generation. This design allows for:
- Unified Processing: All modalities are processed through a single transformer architecture
- Cross-Modal Attention: Direct attention between vision, language, and action tokens
- Scalable Training: Efficient training on large-scale multimodal datasets
Key Components#
- Vision Tokenizer: Converts visual observations into discrete tokens
- Language Tokenizer: Processes natural language instructions
- Action Tokenizer: Represents actions in the same token space
- Unified Transformer: Processes all token types jointly
Experimental Results#
We evaluate OmniJARVIS on various instruction-following benchmarks:
- Minecraft: Significant improvements in task completion rates
- Real-world Robotics: Successful transfer to physical environments
- Language Grounding: Enhanced understanding of spatial and temporal concepts
Impact and Applications#
OmniJARVIS has broad applications in:
- Autonomous robotics
- Virtual assistants
- Game AI
- Educational tools
Citation#
@inproceedings{wang2024omnijarvis,
title={OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open-World Instruction Following Agents},
author={Wang, Zihao and Cai, Shaofei and Mu, Zhancun and Lin, Haowei and Zhang, Ceyao and Liu, Xueije and Li, Qing and Liu, Anji and Ma, Xiaojian and Liang, Yitao},
booktitle={Advances in Neural Information Processing Systems},
year={2024}
}