Abstract#
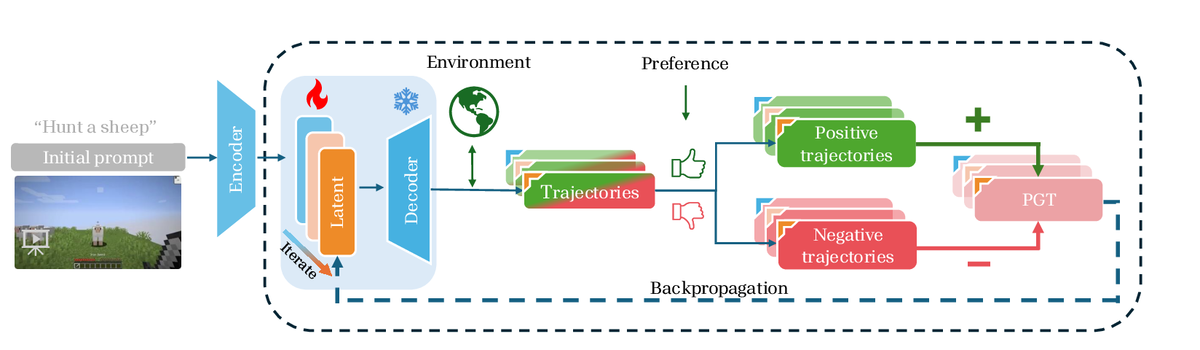
Goal-conditioned policies can express diverse behaviors, but downstream performance is often sensitive to the selected instruction or prompt. This work formulates post-training adaptation as latent control: the policy remains frozen while the goal embedding is optimized with trajectory-level preference feedback.
The resulting approach searches for conditioning inputs that make preferred trajectories more likely and suppress undesirable behavior without changing the physical dynamics learned by the base policy. Experiments on Minecraft SkillForge show that latent-goal optimization can outperform expert-written prompts and improve out-of-distribution robustness compared with full fine-tuning.
Key Ideas#
-
Latent-goal post-training: Adapt a frozen goal-conditioned policy by updating the continuous goal embedding.
-
Trajectory preference learning: Use preferences over rollouts to guide the latent goal toward behaviors that better satisfy task objectives.
-
Robust task alignment: Separate task alignment from policy dynamics so the adapted behavior can generalize better under distribution shift.
Citation#
@inproceedings{zhao2026optimizing,
title={Optimizing Latent Goal by Learning from Trajectory Preference},
author={Zhao, Guangyu and Lian, Kewei and Ru, Haoxuan and Zhang, Borong and Lin, Haowei and Mu, Zhancun and Fu, Haobo and Fu, Qiang and Cai, Shaofei and Wang, Zihao and Liang, Yitao},
booktitle={International Conference on Machine Learning},
year={2026}
}