Abstract#
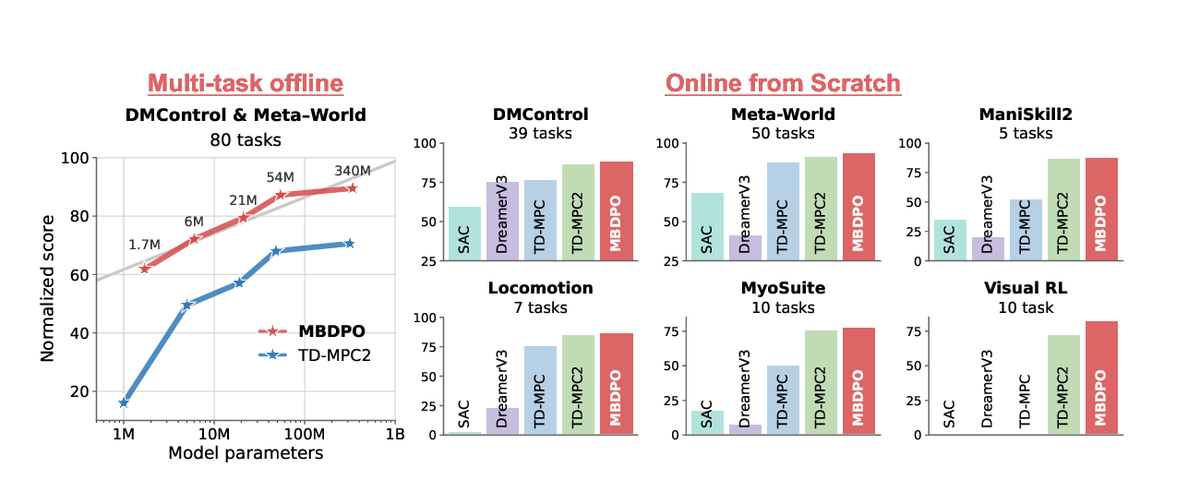
World-model reinforcement learning can scale decision-making through learned dynamics, but long-horizon policy improvement is often limited by model bias and by a mismatch between search and value learning. Model-Based Diffusion Policy Optimization (MBDPO) addresses this by representing policy optimization as a diffusion process over searched trajectories in latent world models.
Rather than relying on a separate planner over the learned model, MBDPO refines a diffusion policy with an implicit energy function extracted from collected data. The paper evaluates the method across multi-task offline pretraining, online learning, and offline-to-online fine-tuning, with scaling studies showing consistent gains as model capacity increases.
Key Ideas#
-
Diffusion policy optimization: Use diffusion policy representations to optimize trajectory distributions in latent world models.
-
Search-policy alignment: Reduce inconsistency between policy improvement and value learning by unifying search with policy optimization.
-
Scaling analysis: Study how world-model RL performance changes under larger datasets and model capacity.
Citation#
@article{cheng2026scaling,
title={Scaling World-Model Reinforcement Learning Through Diffusion Policy Optimization},
author={Cheng, Xiaoyuan and Yuan, Wenxuan and Mu, Zhancun and Zhang, Yuanzhao and Yang, Yiming and Wang, Hai and Sun, Zhuo and Liu, Che},
journal={arXiv preprint arXiv:2605.26282},
year={2026}
}