Introduction#
Offline reinforcement learning (RL) fundamentally requires solving two coupled challenges: faithfully modeling the behavior distribution to ensure constraint satisfaction, and maximizing a value function to achieve policy improvement. As the community moves towards large-scale, multimodal datasets (e.g., OGBench (Park et al., 2025)), the first challenge, modeling, has necessitated the use of highly expressive generative policies, particularly Diffusion Models and Flow Matching (Lipman et al., 2023; Sohl-Dickstein et al., 2015). These iterative models excel at capturing complex, non-Gaussian behavior manifolds that traditional unimodal policies fail to represent.
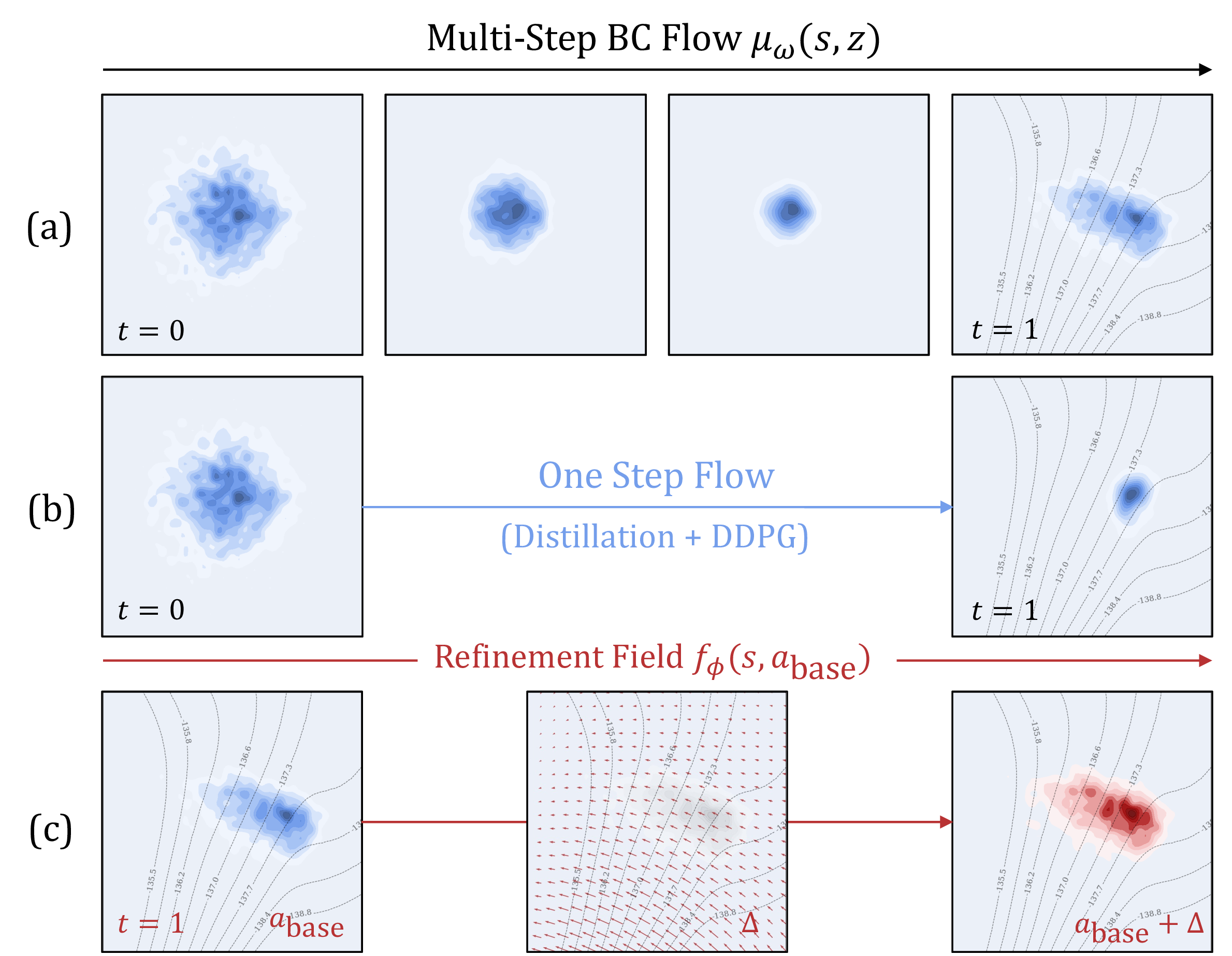
However, extracting a high-value policy from these generative models presents a stark expressivity-optimizability dilemma. Directly optimizing the iterative generation process (solving ODEs/SDEs) for Q-values requires backpropagating through the solver (BPTT), which is computationally prohibitive and numerically unstable. To circumvent this, recent state-of-the-art methods like Flow Q-Learning (FQL) (Park, Li, et al., 2025) attempt to distill the iterative flow into a one-step generator (Figure 1b) to enable tractable joint optimization. We argue that this compression creates a critical expressivity bottleneck. By forcing the complex, iterative generation process into a single step, these methods sacrifice the very modeling capacity they sought to achieve, failing to cover the multimodal support of the dataset and resulting in suboptimal, collapsed policies.
Method#
The philosophy underpinning DeFlow is a structural disentanglement of policy learning. We posit that forcing a single generative model to simultaneously master density estimation (Behavior Cloning) and value maximization (RL) creates a competing objective landscape. To resolve this, we propose a functionally decoupled architecture that leverages the strengths of both worlds.
We formulate the policy as a composite function, where the final action is derived from a Base Flow adjusted by a Refinement Module :
Here, denotes the stop-gradient operator. In this paradigm, acts as a multi-step flow matching model that faithfully learns the behavior manifold, providing a high-quality proposal action. The module , implemented as a lightweight MLP, learns an optimal residual to shift this proposal toward high-value regions.
To train the refinement module, we employ the method of Lagrange multipliers. We first apply Q-Normalization to the RL objective to mitigate the scale variance of -values across different environments. We then introduce a learnable Lagrangian multiplier (where ). The loss function for the refinement module is defined as:
Mirroring the automated entropy tuning found in Soft Actor-Critic (SAC), is automatically adjusted to satisfy the constraint by minimizing:
Beyond its performance in static datasets, the decoupled nature of DeFlow offers a principled framework for the transition from offline pre-training to online fine-tuning. In the online phase, a notorious challenge is maintaining the integrity of the learned behavioral prior while allowing for further exploration. Under our paradigm, the Base Flow can be effectively frozen to serve as a high-fidelity manifold anchor, significantly reducing the computational overhead and stabilizing the distribution. Meanwhile, the Refinement Module retains its plasticity, evolving to capture new high-reward regions with the auto-tuned multiplier .
Experiments#
Our experiments are conducted on 73 challenging offline RL tasks and 15 O2O RL tasks.
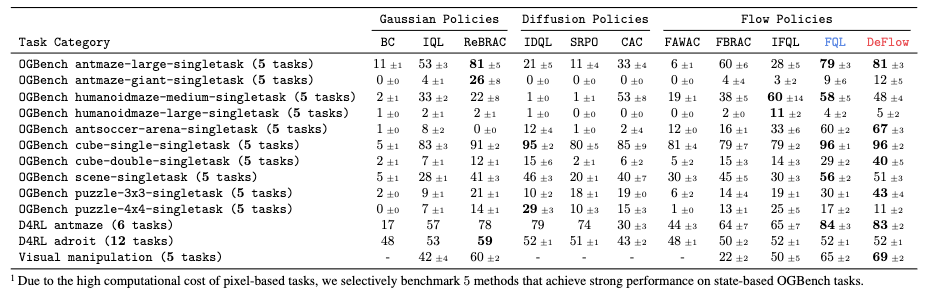
DeFlow achieves SOTA or near-SOTA performance on the majority of benchmarks, with significant margins in highly multimodal tasks like cube-double-play and puzzle-3x3-play. This superiority validates DeFlow’s capability to model complex action distributions where prior methods struggle due to limited expressivity. Notably, DeFlow achieves these results without extensive hyperparameter tuning, demonstrating both robustness and simplicity.
Unlike the behavioral cloning weight , which often requires extensive tuning, represents a physical constraint reflecting the action manifold width. To quantify this, we compute the Intrinsic Action Variance (IAV, denoted as ) using the average variance of actions among -nearest neighbors. Empirically, we set proportional to the estimated deviation (e.g., for fine manipulation and for navigation). Crucially, our adaptive Lagrangian multiplier ensures robustness to rough estimates of , effectively eliminating the need for grid search.

we visualize the action landscapes of critical states in cube-double-play. We identify two primary failure modes in one-step methods like FQL:(i) Mode Collapse, where the policy prematurely averages distinct modes into a single, often invalid, mean action (Figure 2a); (ii) OOD Drift, where aggressive value maximization drives actions off the data manifold (Figure 2b). In contrast, DeFlow mitigates these issues through its decoupled architecture. The multi-step Base Flow robustly captures the multimodal topology of the data, acting as an anchor. The Refinement Module then performs constrained, local adjustments. This design ensures that policy improvements remain strictly within the valid support, which is decisive for high-precision manipulation tasks.
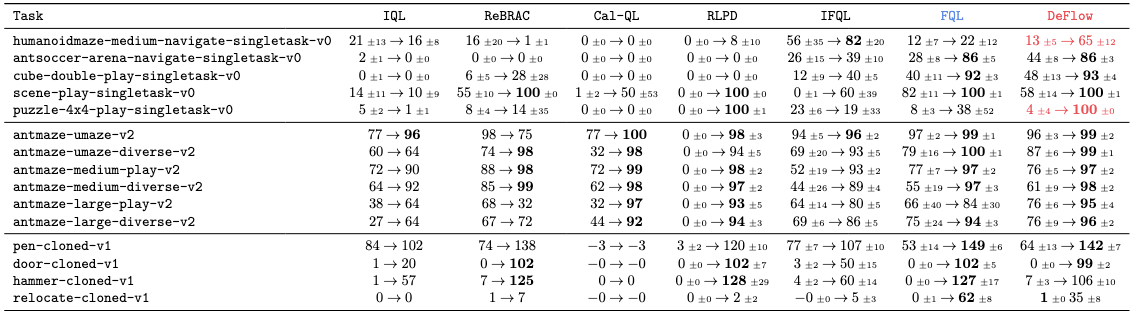
For offline-to-online tasks, DeFlow matches or exceeds the state-of-the-art (e.g., FQL), achieving remarkable gains in complex tasks like humanoidmaze-medium. A critical advantage of DeFlow is its seamless transition from offline to online. Unlike prior works that often necessitate altering hyperparameters (or “loosening” constraints) to encourage exploration, DeFlow requires zero additional tuning. We maintain the exact offline configuration, relying on our automatic tuning to naturally balance exploration. While this strict adherence to a unified protocol may limit performance in tasks with poor data quality (e.g., relocate-cloned), it ensures empirical rigor and demonstrates the method’s inherent robustness without task-specific engineering.
Discussions: What’s Next?#
As a closing remark, rather than claiming DeFlow as a definitive solution, we position it as a lens to re-examine the interplay between generative diversity and critic-guided optimization. Our findings suggest that while modeling the behavior distribution is a solved problem with modern generative models, effective policy extraction remains a nuanced challenge where “more optimization” does not always equate to better performance.
The Saturation of Inference Scaling. A pivotal insight from our analysis is the counter-intuitive behavior of inference-time scaling. We observed that standard strategies like rejection sampling yield minimal gains within our framework. We attribute this to a Trust Region Saturation phenomenon: DeFlow’s refinement module is designed to be aggressive—it efficiently pushes the proposal to the boundary of the manifold constraint () in a single forward pass. Consequently, the “optimization budget” allowed by the behavior prior is fully consumed. Any further attempts to maximize Q-values (e.g., via rejection sampling) tend to exploit the critic’s approximation errors (adversarial OOD peaks) rather than uncovering legitimate high-value modes. This reveals a critical boundary in offline RL: simply “sampling more” is futile when the valid optimization landscape is already saturated.
Rethinking Policy Extraction. This finding suggests that the bottleneck in modern offline RL has shifted. The challenge is no longer about generating diverse behaviors (which flow models handle well), but about navigating the treacherous signal-to-noise ratio of the learned Q-function. DeFlow demonstrates that a deterministic, constrained gradient step could be safer and more effective than stochastic search in this landscape. Looking forward, we posit that the next breakthrough lies not in blind maximization, but in Manifold-Aware Sampling—incorporating methods like constrained Langevin dynamics or gradient-guided flow that can explore the value landscape while explicitly adhering to the complex topology of the behavior manifold, thereby avoiding the OOD pitfalls that plague current extraction techniques.