Introduction#
Offline reinforcement learning needs to improve a policy while staying within action regions supported by a fixed dataset. This becomes difficult on multimodal benchmarks such as OGBench (Park et al., 2025), where nearby states can admit several distinct but reasonable actions.
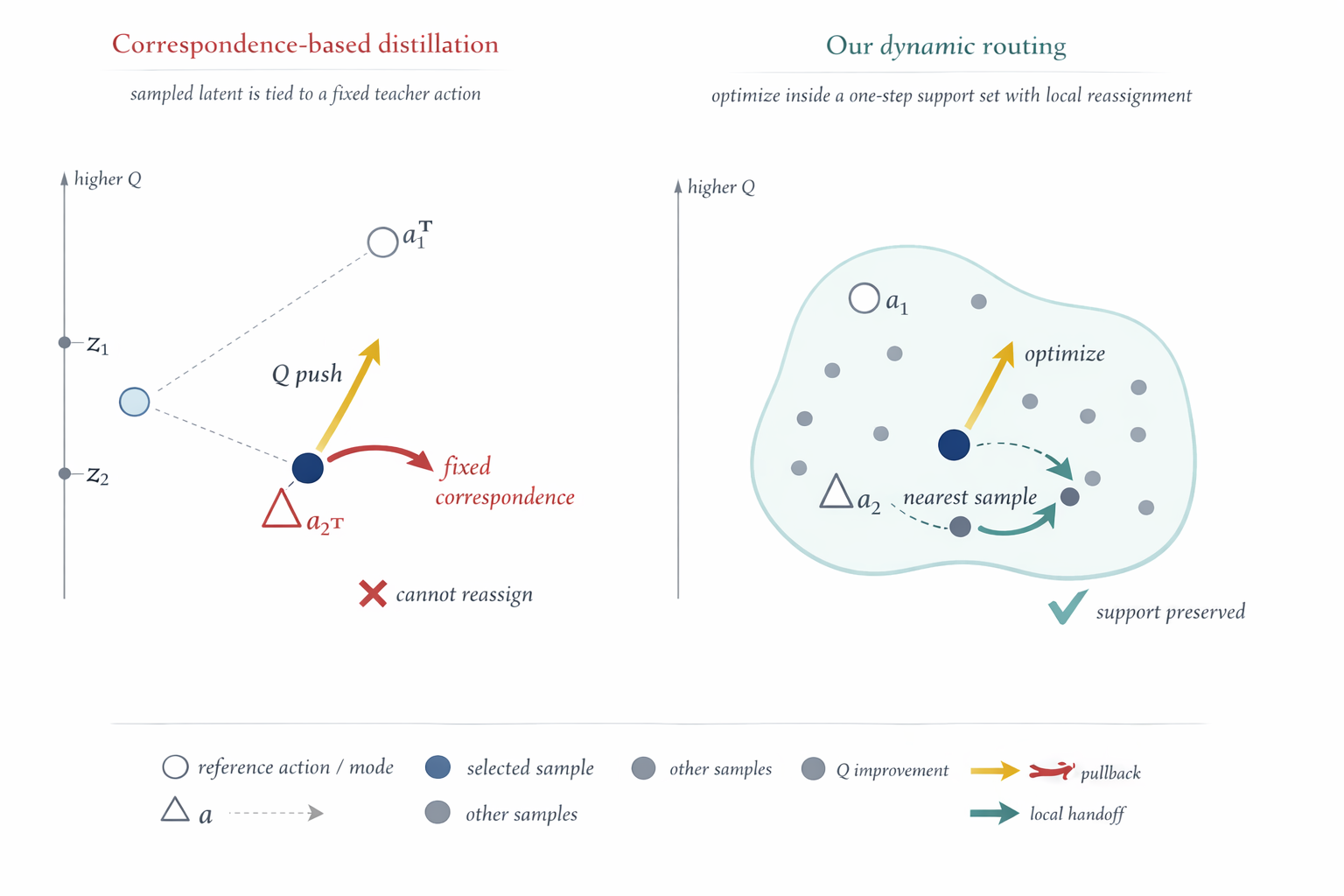
Many strong generative offline RL methods rely on iterative sampling during training, inference, or both. A one-step actor avoids that cost, but pointwise extraction methods such as Flow Q-Learning (FQL) (Park, Li, et al., 2025) can force the same sampled output to both move toward higher value and stay close to its paired teacher endpoint. When those directions disagree, the update becomes a compromise on that sample.
DROL argues that the useful constraint is local support, not fixed latent-to-teacher correspondence. If responsibility for a supported region can transfer across candidates during training, one candidate can move toward a better local action while another retains the old neighborhood.
Method#
DROL keeps a latent-conditioned one-step actor, but changes how behavior support is regularized during training. For each state, it samples a candidate set:
Each dataset action is routed to its nearest current candidate:
Only the routed winner receives the behavior cloning and critic-guided actor update. Because routing is recomputed at every gradient step, candidate ownership can change as the actor geometry evolves. At test time, DROL uses a single latent sample, so deployment remains in the plain one-step setting.
Theory#
DROL is motivated by three local observations about routed actor updates. The goal is not to prove global offline RL convergence, but to explain why winner-only routing can preserve support while still allowing critic-guided improvement.
Separated Neighborhoods Avoid Collapse#
In a local state neighborhood with several separated action regions, routed behavior cloning behaves like a local quantization objective. If two candidates serve the same supported region while another region has none, the average reconstruction distance increases. A simple one-dimensional separated-interval model shows that, when the number of candidates matches the number of separated regions, every global minimizer places one prototype in each interval. This explains why winner-only updates do not necessarily collapse all candidates to one mean action.
Routing Replaces a Persistent Tether#
Pointwise extraction keeps a fixed pullback term between a sampled output and its paired teacher endpoint. For a single candidate and target , the local objective
always contains the same tether . Under routing, the behavior cloning term is attached only to the nearest candidate. If another candidate becomes closer to the same target, the pullback transfers to that new winner. This lets one candidate move toward a higher-value action while another takes over the old supported neighborhood.
Larger K Improves Handoff Availability#
The routing budget controls how many local actions are visible during a training update. If a reachable modal neighborhood has probability of being hit by one latent sample, then the probability that a -candidate set covers all reachable neighborhoods is lower bounded by
Increasing does not create new supported actions; it makes it less likely that the current candidate set misses a reachable local mode. This is why large or highly multimodal task families can benefit from a larger routing budget.
Experiments#
DROL is evaluated on OGBench (Park, Frans, et al., 2025) and D4RL (Fu et al., 2020). The experiments ask whether routed training can make a plain one-step actor competitive with stronger generative offline RL baselines, whether candidate sets actually avoid collapse, and how the routing budget affects performance.
Benchmark Results#
DROL(16) uses a fixed default routing budget of . DROL* keeps the rest of the training setup unchanged and selects once for each benchmark family.
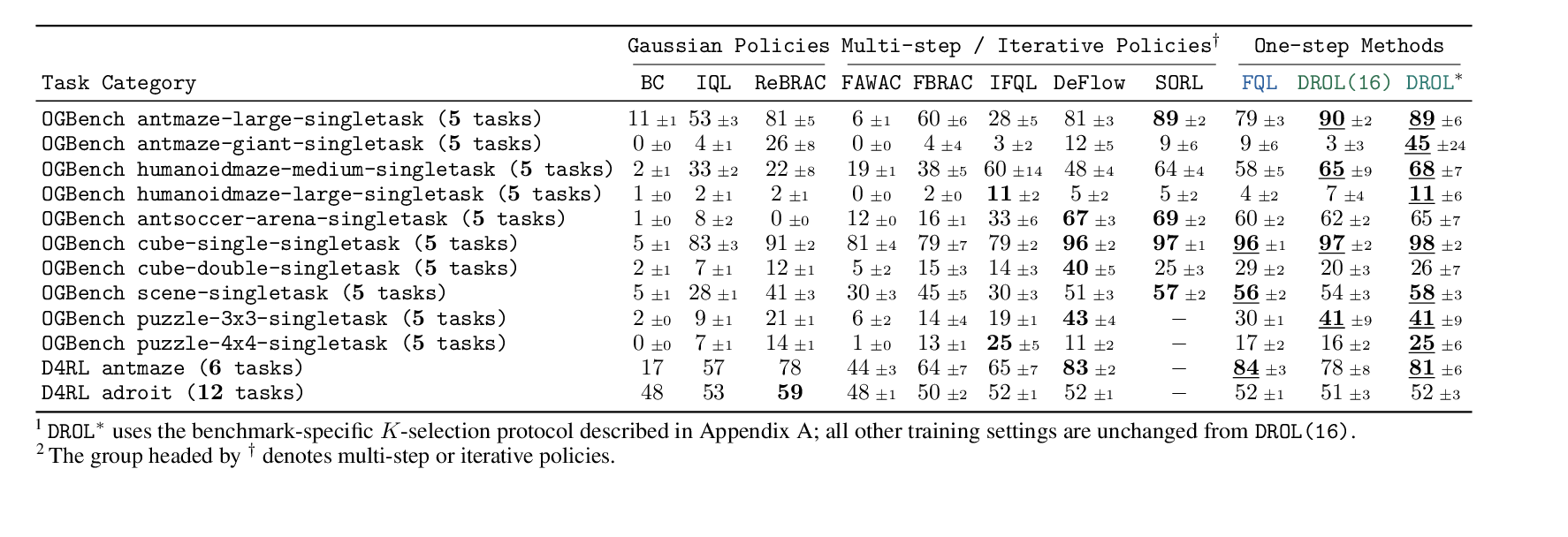
With the fixed default configuration, DROL matches or improves over the one-step FQL baseline on most OGBench groups, including clear gains on antmaze-large, humanoidmaze-medium, antsoccer, cube-single, and puzzle-3x3. With benchmark-family K selection, DROL* improves or matches FQL on 9 of the 10 OGBench groups and remains close on D4RL.
Mechanism Visualizations#
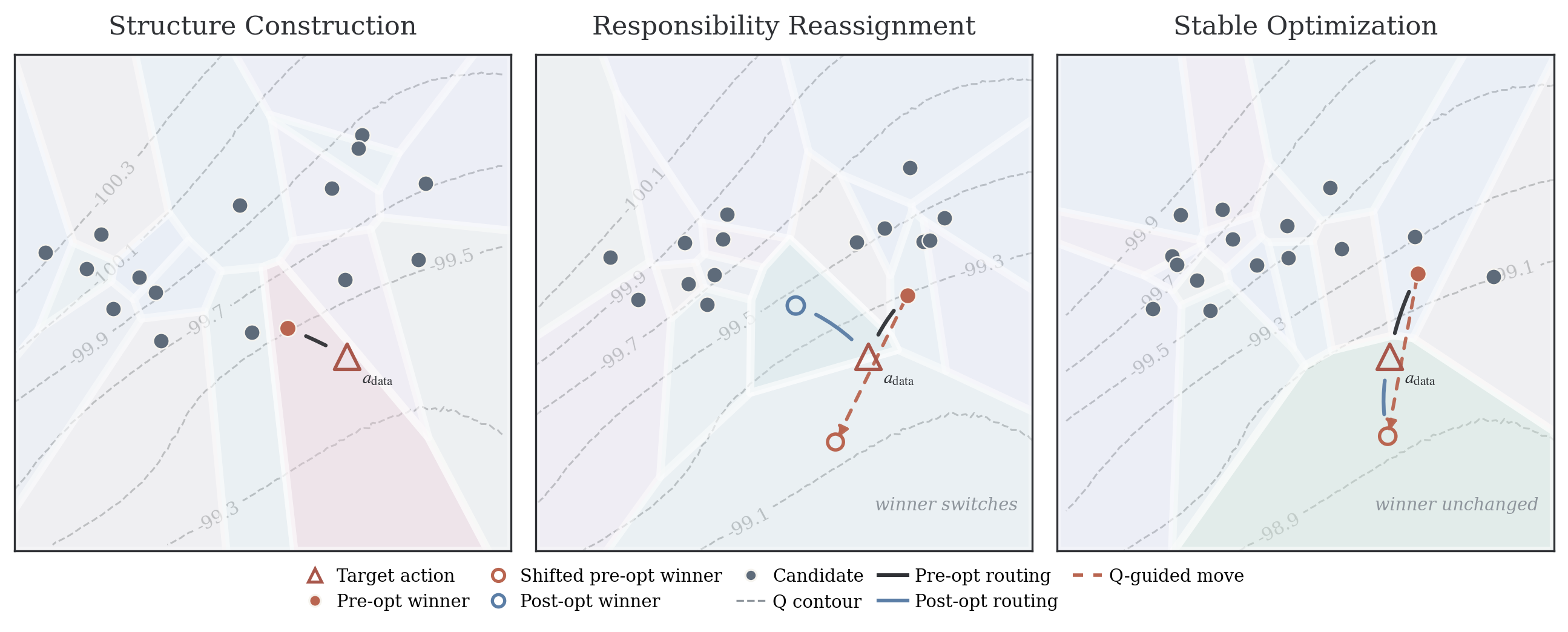
The Voronoi visualization shows how the candidate set induces local responsibility regions. Early in training, candidates spread rather than collapse. Later, two common regimes appear: one candidate can hand off responsibility to another, or the same candidate can keep responsibility while making a stable local improvement.
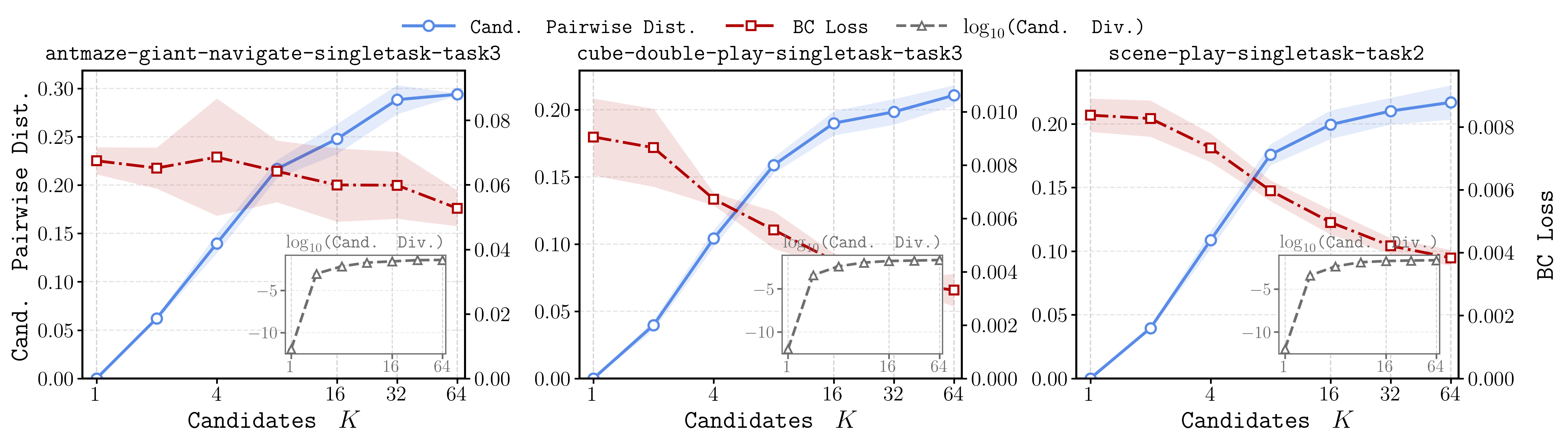
The candidate-scaling curves show that larger increases candidate spread and lowers routed behavior-cloning loss. This is consistent with the theory: larger candidate sets provide finer local coverage of supported action neighborhoods rather than simply duplicating the same action.
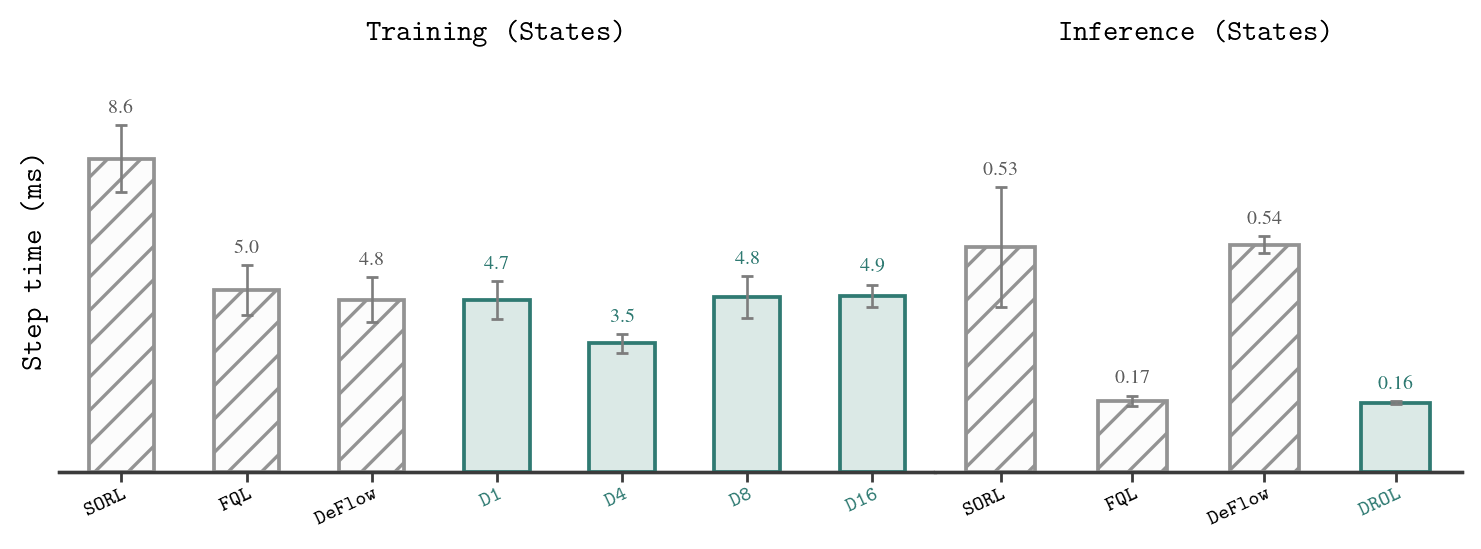
The runtime comparison separates training-time candidate evaluation from deployment. Training cost grows with , but inference remains cheap because the final policy still uses a single latent sample and one actor pass.
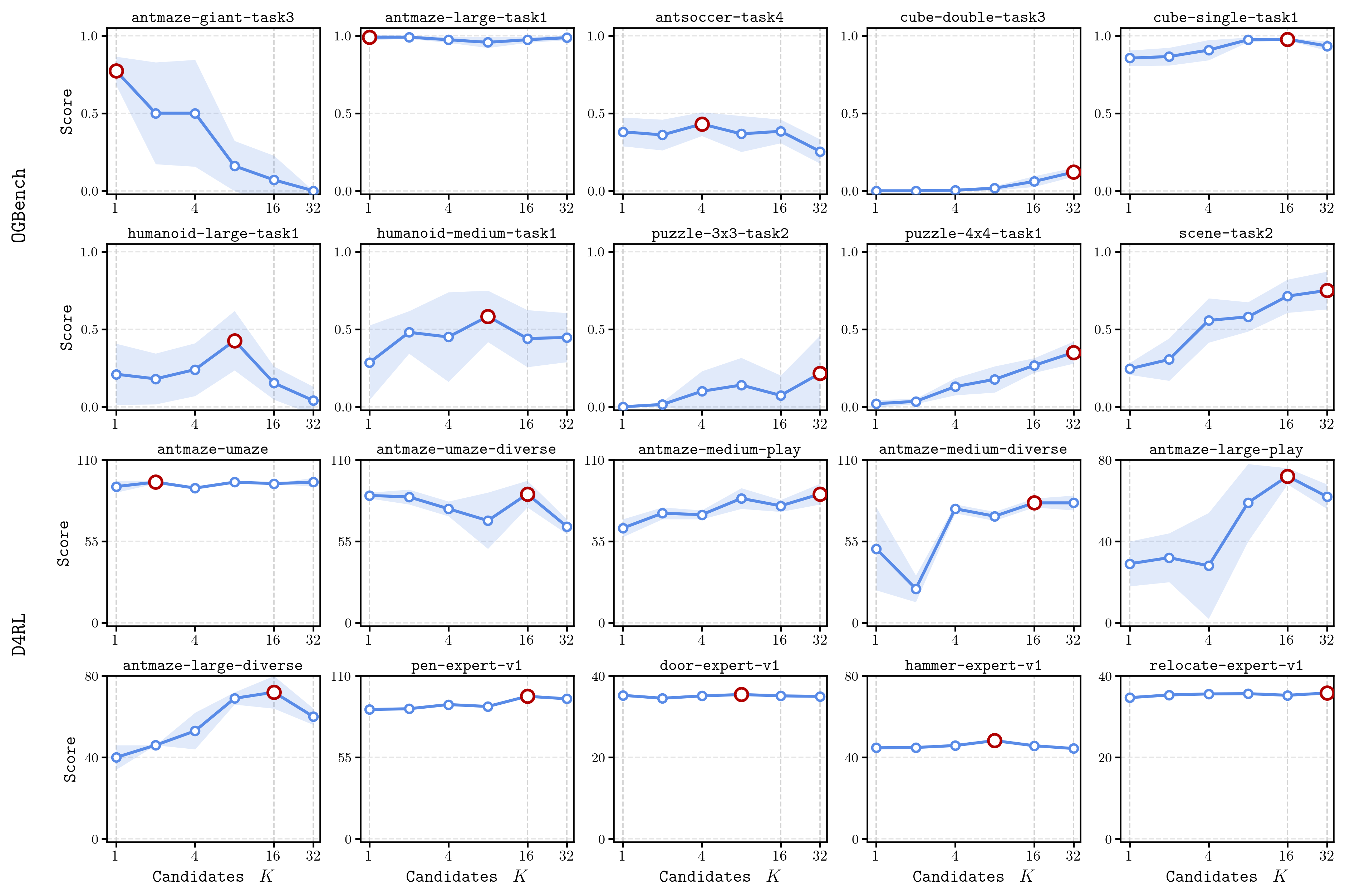
The K-sweep results show that is a routing-capacity parameter, not a monotone performance knob. Large multimodal navigation families often benefit from higher , while other environments saturate earlier or prefer intermediate values.
Conclusion#
DROL studies one-step actor learning in multimodal offline RL from a geometric perspective. Instead of preserving a fixed pointwise correspondence between each latent sample and a teacher endpoint, it preserves support through a routed candidate set. This lets responsibility transfer as optimization progresses: one candidate can follow the critic toward a better local action while another remains available to cover the old supported region.
The method keeps deployment close to standard one-step baselines because multiple candidates are used only during training. Its limitations are also clear: the theory is local rather than a full convergence proof, the method depends on a fixed routing budget , Euclidean nearest-neighbor matching, and extra training-time candidate evaluations. Natural next steps include learned routing metrics, adaptive candidate budgets, softer responsibility sharing, and region-level support regularization.